Table of Contents
Trustworthy AI
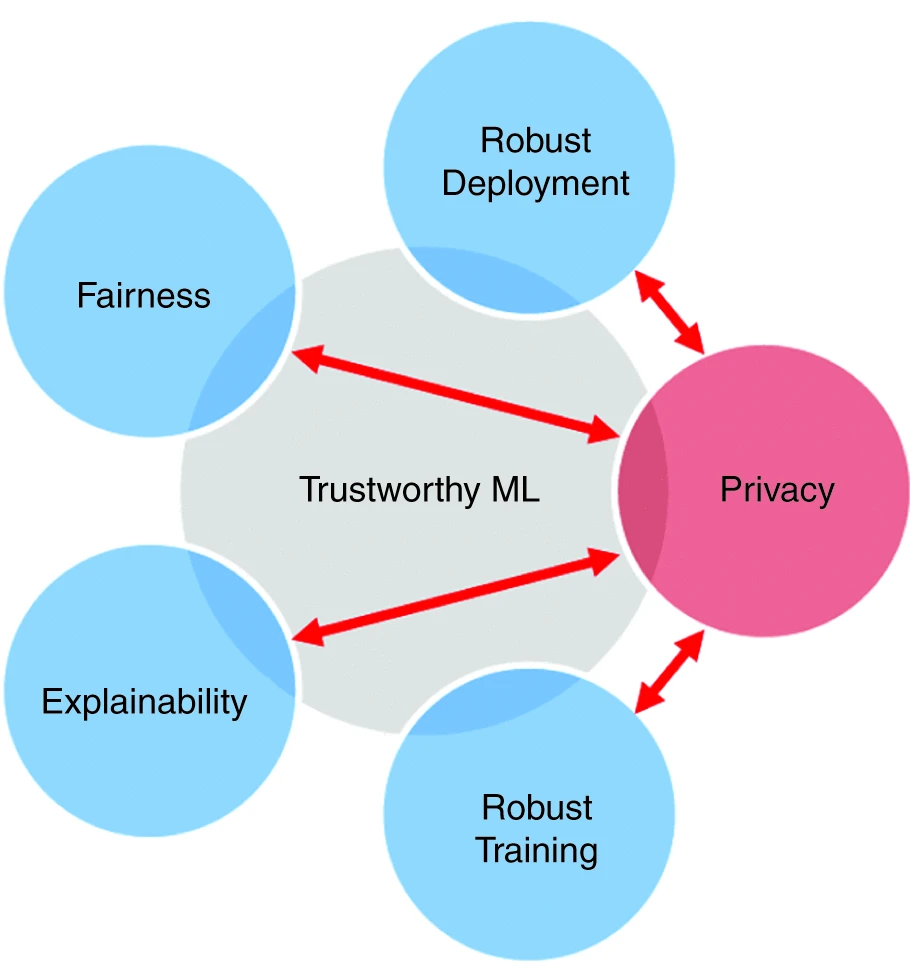
While machine learning (ML) has shown remarkable success in many applications such as content recommendation on social media platforms, medical image diagnosis, and autonomous driving, there is a growing concern regarding the potential safety hazards coming with ML. As exemplified in Figure 1, people are interested in multi-facets evaulation of machine learning models besides accuracy.
My current research focuses on three main aspects: data privacy, model privacy, and model fairness.
Data and Model Privacy
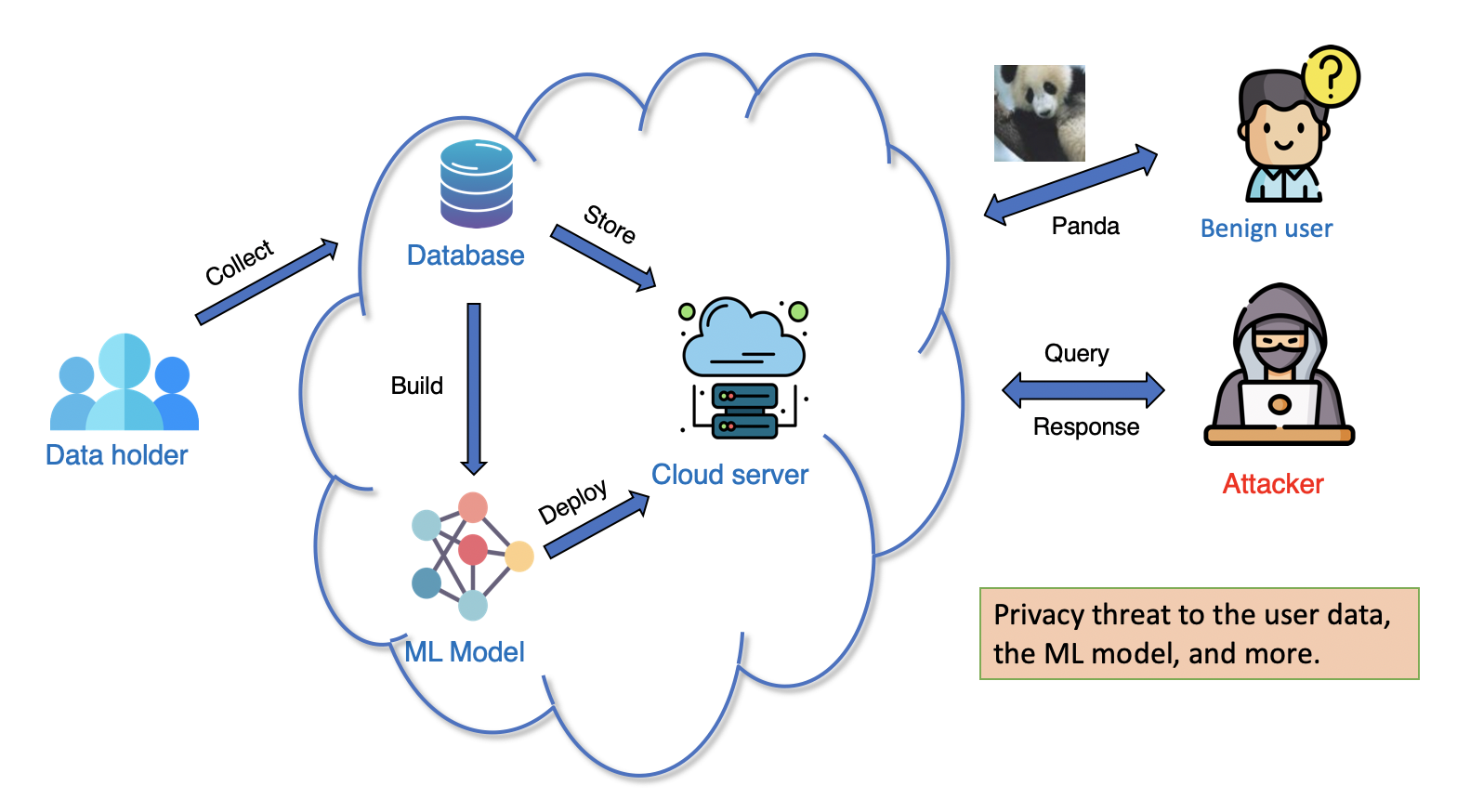
The privacy threat is inconspicuous but widely exists in our daily lives. We risk privacy leakage for every step in the machine learning life cycle, such as collection, storage, release, and analysis, as illustrated in Figure 2. Our goal is to develop privacy-preserving methods with built-in privacy guarantees, especially for the collected data and built models.
Data privacy pertains to the protection of sensitive information collected to build ML models. We have proposed a novel approach called Subset Privacy for protecting categorical data and developed an open-sourced software implementation. We have demonstrated its usage in multiple learning tasks and shown its potential to be useful in a wide range of fields beyond statistics due to its unique user-friendly implementation.
In addition to data privacy, the reliability and security of the ML models built from the collected data are of paramount concern, which we refer to as model privacy. We have formulated the Model Privacy framework that can be applied to analyze multiple model attacks including stealing and backdoor attacks.
Model Fairness
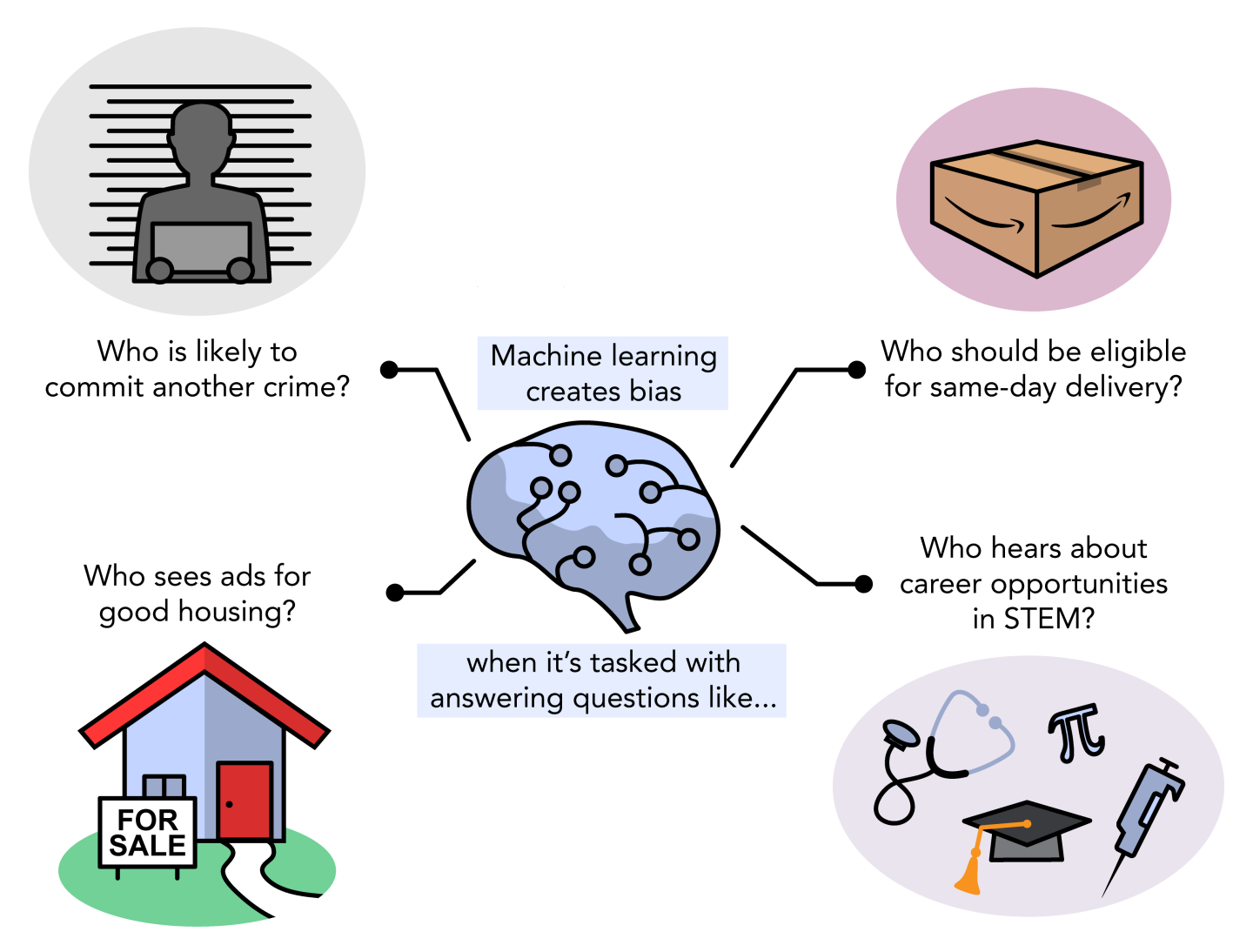
The fairness of the ML model has attracted significant attention nowadays, especially in areas such as criminal justice and banking. It is well-known that ML models may inadvertently be unfair. For example, the COMPAS algorithm, which assigns recidivism risk scores to defendants based on their criminal history and demographic attributes, was found to have a significantly higher false positive rate for black defendants than white defendants, thereby violating the principle of equity on the basis of race.
Our goal is to build a model that makes equitable decisions for different groups in the population. We have identified the conditions under which a broad class of distributed ML algorithms can produce fair models. Additionally, we have proposed a new algorithm, named FedGFT, that directly optimizes model fairness with theoretical guarantees.
Other Safety Aspects
Explainability: We studied the effect of the LASSO regularization on variable selection in terms of neural networks. Our understanding indicates that neural networks can consistently select significant variable while achieving satisfactory accuracy.
Model compression: An emerging demand of machine learning models is to reduce the model size while retaining a comparable prediction performance to address limitations in computation and memory. We investigated a fundamental problem in model pruning: quantifying how much one can prune a model with theoretically guaranteed accuracy degradation. Insipred by the developed theory, we proposed a data-driven, adaptive pruning algorithm.
Recent Work on Certifiable Evaluation of LLMs
As foundation models continue to scale, the size of trained models grows exponentially, presenting significant challenges for their evaluation. Current evaluation practices involve curating increasingly large datasets to assess the performance of large language models (LLMs). However, there is a lack of systematic analysis and guidance on determining the sufficiency of test data or selecting informative samples for evaluation.
The current evaluation approach, which we call the static evaluation process, is simply reporting the average score over the entire test dataset. However, this static evaluation approach does not quantify or guarantee the reliability of the result and is not sample efficient. In response, we propose a certifiable online evaluation process, named Cer-Eval, that sequentially refines evaluation results until a user-defined estimation error and confidence level is reached.